Services
SERVICES
SOLUTIONS
TECHNOLOGIES
Industries
Insights
TRENDING TOPICS
INDUSTRY-RELATED TOPICS
OUR EXPERTS

June 9, 2026

Recommendation systems based on machine learning (ML) algorithms are powerful engines that deliver personalized product or content suggestions by analyzing user data and behavioral patterns, such as purchase history, browsing activity, likes, and reviews.
With 5+ years of experience in machine learning development services and an internal AI/ML Center of Excellence, Itransition helps businesses build advanced recommender engines to drive sales and deliver tailored customer experiences.
expected product recommendation engine market size in 2026
The Business Research Company
expected content recommendation market size in 2033
S&S Insider
CAGR of streaming & digital media share on the content recommendation engine market by 2033
S&S Insider
of retailers are currently investing in AI-powered systems for personalized recommendations
NVIDIA
Study period
2019 - 2030
CAGR (2025 - 2030)
33.06%
Fastest Growing Market
Asia-Pacific
Largest Market
Asia Pacific
Market Concentration
Low
Major players
Scheme title: Global recommendation engine market forecast
Data source: mordorintelligence.com — The recommendation engine market
Most recommendation engines fall into three major sub-categories depending on the approach used to select and recommend products or services.
Recommendation engines in this category rely on machine learning algorithms, such as clustering models, regression, user-based k-nearest neighbors, matrix factorization, and Bayesian networks, to survey customers’ perceptions of products. After identifying customer preferences for certain products, the engine will offer items already bought by other users with similar tastes. The system can gather customer information via explicit data collection (asking them to compile a list of favorite items and rate previously purchased products) or implicit data collection (monitoring user behavior on social media and user-item interactions like purchases and browsing on ecommerce websites).
Cold start problem: providing valuable suggestions to new users with no purchase history can be challenging based on only available parameters (gender, age, etc.).
Data sparsity: in cases with a large product catalog, each item may not have a sufficient number of user reviews to analyze, reducing the recommendations' accuracy.
Shilling attacks: new items are vulnerable to user rating manipulations (such as negative reviews from competitors).
Content-based recommendation systems that follow this approach mainly consider the item's characteristics, such as price, category, and other features defined by assigned metadata tags (essentially keywords), along with user preferences interpreted from their purchases and related feedback. Based on these parameters, a machine learning algorithm (be it Bayesian classifiers, decision trees, clustering, etc.) will recommend other products sharing similar features with those previously bought and positively reviewed.
Many recommendation systems embrace a hybrid approach combining collaborative and content-based filtering. There are several ways to hybridize them. The mixed hybridization technique involves providing users with both collaborative and content-based suggestions at the same time. The weighted technique, on the other hand, implies merging the score calculated via two different approaches. Another combination trick, namely meta-level, implies using the output of the first approach (basically the machine learning model built by algorithms) as an input source for the second one.
Scheme title: Meta-level technique
Data source: researchgate.net — A Hybrid Recommendation System
Whether based on collaborative or content-based filtering, ML-powered recommendation systems follow a multi-stage pipeline to generate personalized suggestions.
A machine learning system needs large data sets to segment customers, namely categorize them into a certain archetype or buyer persona according to their attributes, and target them with suitable suggestions. Relevant metrics can include browsing behavior, purchase history, content usage, personal information from user profiles, product reviews, access devices, and many more. The system can gather this information via explicit or implicit data collection, while product features can be obtained from the related tags.
Data sets should be consolidated into a suitable repository depending on the type of data a recommender system needs to analyze. Along with traditional SQL databases designed to efficiently store structured data, you can use NoSQL databases that handle complex formats, such as unstructured data. Data warehouses, on the other hand, can easily integrate information from multiple sources and prepare it for analysis, while data lakes act as flexible repositories to ingest data in any format.
Scheme title: AWS-based recommender system architecture with an Amazon S3 data lake
Data source: AWS — Architecting near real-time personalized recommendations with Amazon Personalize
The recommendation system leverages machine learning algorithms to process data sets, identify patterns and correlations among multiple variables, and build ML models portraying them. For example, algorithms can identify a recurring connection between the age of customers and their preference for one brand over another. Trained models can make predictions on user preferences and recommend the most relevant content or products which companies then base their decisions upon.
Scheme title: ML model training and output generation
Data source: NVIDIA
Recommendation engines can incorporate a variety of machine learning algorithms to process data and provide suggestions. Here are the ones that many ML researchers and practitioners are currently focusing on:
This class, which includes algorithms like ALS and SVD, is currently the most popular option for collaborative filtering. Matrix factorization algorithms identify the relationship between items and users (purchases, ratings, etc.) and describe them via a user-item matrix. Users with similar relationships will also receive similar recommendations.
These are a type of deep neural networks that compress input data down to its core features. They can be used in collaborative filtering to derive key user traits from their interactions with items and provide accurate recommendations.
These deep neural networks can identify relationships across sequential data points. For instance, they can monitor the sequence of user interactions in a session (such as movies viewed) to predict what content the user might be interested in watching next and recommend it.
Nowadays, all major digital service providers and ecommerce enterprises rely on large-scale recommendation systems handling extensive product catalogs and user bases to deliver a tailored customer experience and enhance sales performance or advertising revenues.
Amazon leverages a recommendation algorithm for products or search results, combining in-site suggestions based on several strategies (recommended for you, bought together, recently viewed, etc.) with off-site recommendations via email. The ecommerce leader deployed its collaborative filtering-based recommender engine between 2011 and 2012 and later moved from item-based collaborative filtering to a system based on autoencoder neural networks.

YouTube implemented a recommendation system to prioritize certain videos, suggest channel subscriptions, and provide relevant news. The engine takes into account a variety of parameters, defined as "signals" to better frame user interests, including clicks, likes and dislikes, survey responses, watch time, and shares. In addition to personalizing user experience, this system aims to promote high-quality information while demoting problematic content, such as sensationalistic tabloid news or racy and violent videos.
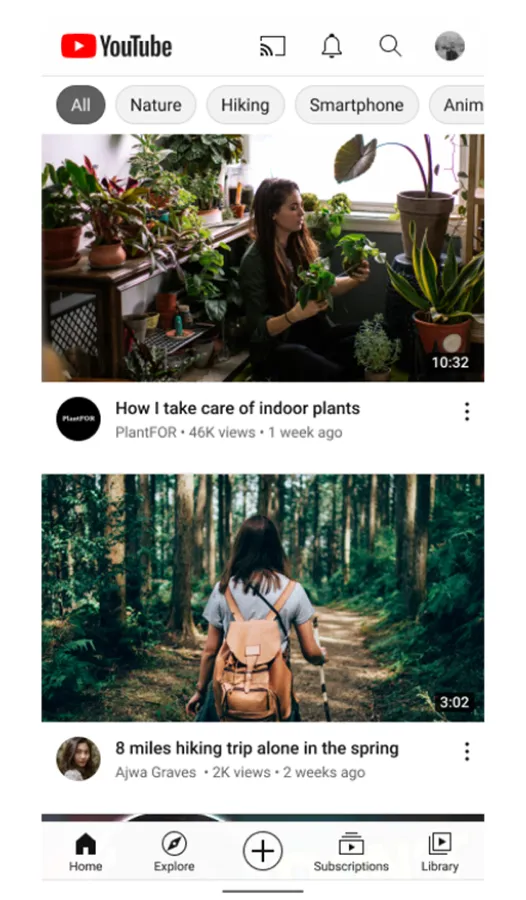
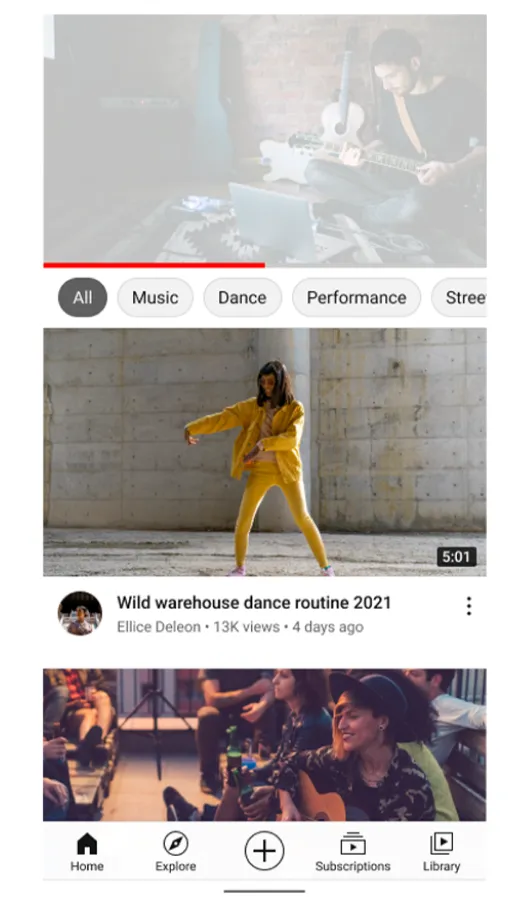
Image title: Youtube’s recommendations on the homepage and "up next" videos
Data source: blog.youtube — On YouTube’s recommendation system
The market-leading streaming service relies on a recommendation system powered by deep learning models to provide movie recommendations. Its algorithms consider variables such as user features (including browsing history and ratings issued), movie type and popularity, and item-item similarity with previous content to sort the groups of movies displayed in horizontal rows on its home page. The engine also monitors strictly contextual features, such as the day of the week, seasonality, national festivities, device, and more.

LinkedIn deployed a recommendation system to suggest job ads, connections, and courses. One of its core applications is LinkedIn Recruiter, a comprehensive HR tool that compiles lists of suitable candidates for an open position and ranks them depending on their skills, experience, and location. The talent search engine considers both the relevance of certain candidates to a given query and the mutual interest between such professionals and recruiters (essentially, if the candidate positively replies to an InMail message from the recruiter).
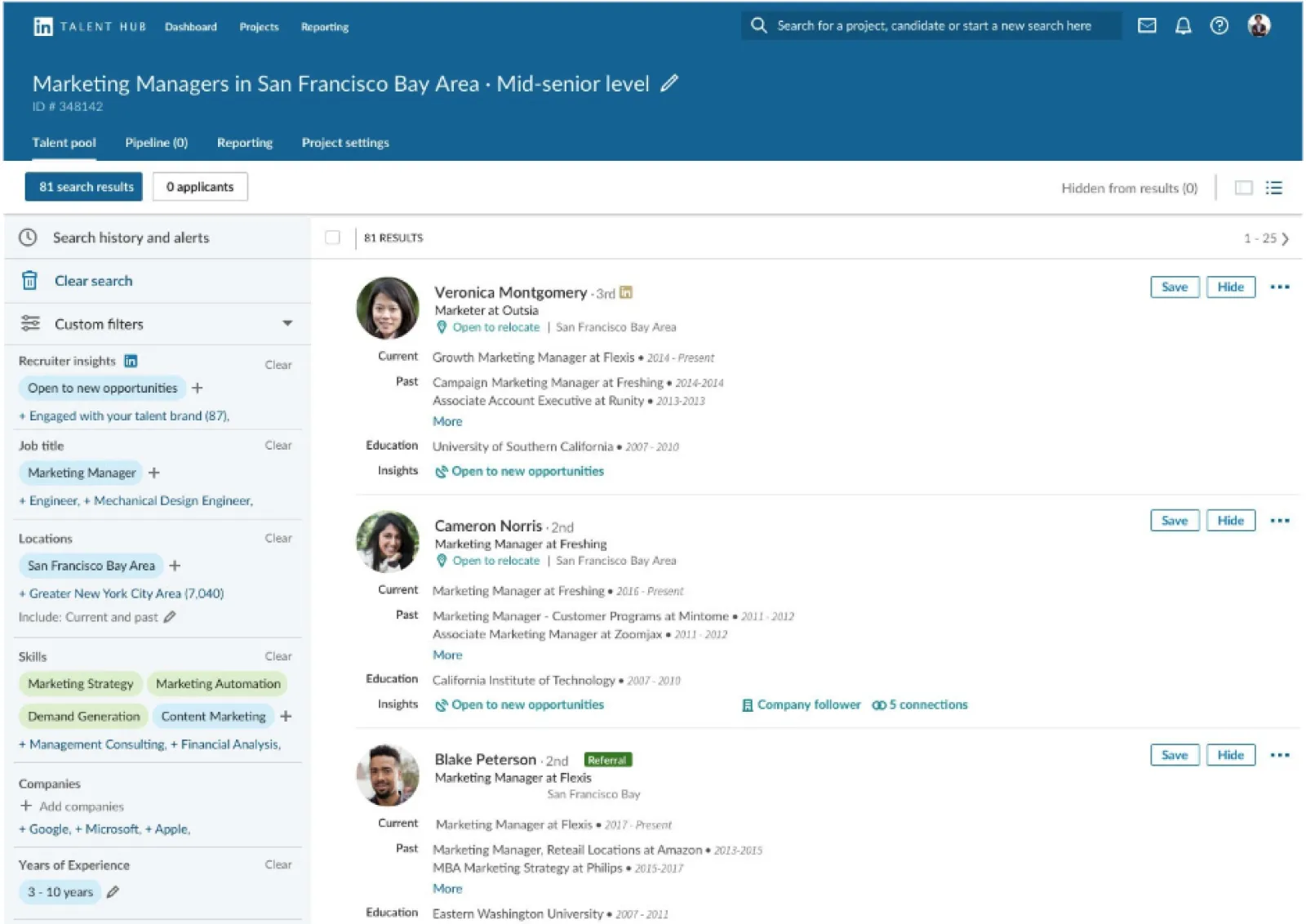
Image title: LinkedIn Recruiter’s dashboard
Data source: LinkedIn
Facebook uses a recommendation engine based on deep learning and neural networks (known as DLRM or deep learning recommendation model) for friend suggestions and news feed sorting, but also to recommend groups, pages you could be interested in, or products on its marketplace. The DLRM processes both continuous features (such as age) and categorical features (including product category) detailing items and platform users. Categorical features are described through embeddings, which are representations of words via real-valued vectors.
Video title: How Facebook’s DLRM operates
Data source: Facebook
Select a filtering approach that suits your business scenario, including your target audience and product range, as well as the data available. For example, ML-powered retail platforms with extensive product catalogs often utilize the hybrid approach to achieve high performance and address the wide range of tasks they have.
Adopt different recommendation strategies depending on the customer journey stage. For example, first-time users could be directed towards the "most popular" products, as their interests haven’t yet been defined. On the other hand, visitors with a long purchase history can be targeted with more relevant recommendations based on user affinity with certain categories of merchandise.
Different page contexts can also call for specific recommendation strategies. Сonsider adopting the “most popular” strategy for your home page and “similar items” for product pages. Regarding cart pages, it's worth embracing a “bought together” strategy to encourage upselling.
You can build your recommender engine based on a three-stage architecture to better handle large item catalogs and improve accuracy. First, the system narrows down your catalog to a smaller subset of items (candidates). Then, due to the smaller pool of candidates, the solution can use a more complex ML model and consider more item features to score and rank potential items to suggest. Finally, the engine refines the candidate ranking based on additional factors such as freshness (latest purchases, content recency, etc.) to provide relevant suggestions.
Building recommender systems fully tailored to your needs can be a good option, but only if you are ready to face higher upfront costs for its development. Otherwise, you can rely on cloud-based services and tools providing built-in algorithms, pre-trained ML models, and APIs to receive model output. These include Salesforce Interaction Studio, Adobe Target, Amazon Personalize, Optimizely, IBM Watson Real-Time Personalization, and more. Additionally, various Python libraries provide ready-to-use algorithms to power recommender engines.
Machine learning-based recommendation systems help replicate in-store customer care and personalized guidance offered by a real salesperson in a virtual environment, directing users towards the product they want and boosting their engagement and satisfaction.
Personalizing the shopping experience and highlighting relevant products result in a higher number of items per order, increased average order value, enhanced customer retention and lifetime value, and, therefore, revenue growth.
Along with targeted advertising and triggered communications, recommendation systems can help mitigate marketing costs. In this regard, McKinsey highlighted that product recommendations can improve marketing-spend efficiency by 10-30%.
Itransition provides full-cycle ML services to help you implement powerful recommendation systems and other bespoke AI solutions.
Itransition’s consultants offer expert guidance to streamline your ML project, effectively address technical challenges, and make the most of the resulting solution.
Itransition develops ML solutions tailored to your unique needs and industry specifics or enhances existing software in line with evolving tech and business trends.

Recommendation systems offer a synthesis between the needs of customers and businesses, enabling a more
personalized and enticing user experience while helping companies improve their sales performance.
On the flip side, these data-driven technologies are computationally demanding and can create tension between sheer
performance and the growing demand for privacy and data protection from both the public and legislators. With holistic
expertise in artificial intelligence, machine learning, and data science, Itransition can help you overcome these
challenges and streamline your ML implementation project.
According to Grand View Research, collaborative filtering-based engines are currently the most popular type on the market, while the hybrid system segment seems set to expand at the highest CAGR.
Recommendation systems relying on deep neural networks outperform those based on "traditional" machine learning algorithms in a variety of studies, according to Amazon’s research. Thanks to their complex, multi-layered structures with interconnected nodes, neural networks can better identify non-linear relationships among data points. However, they require superior computational resources, wider training data sets, and extensive hyperparameter optimization to tune the learning process.
Recommender engines can leverage both supervised and unsupervised learning. For instance, they rely on supervised learning to handle labeled data, such as product ratings. However, they can also use k-means clustering, an unsupervised learning algorithm, to make inferences from data sets without labels and aggregate data points with certain similarities.
Recommendation systems can be used in a variety of industries, including:
Retail & ecommerce
Providing customers with personalized product recommendations based on their purchase patterns.
Media & entertainment
Suggesting content (movies, videos, music, etc.) and individual user profiles or groups.
Finance
Recommending suitable financial products such as credit cards, loans, or insurance policies.
Healthcare
Providing patients with suggestions on treatments, nutrition, exercise, etc.

Insights
Explore the role of predictive analytics in ecommerce, its benefits, as well as challenges and solutions to them to implement predictive analytics effectively.

Insights
Explore how virtual stores bridge the gap between online and in-store shopping, helping retailers better engage with customers through immersive experiences.

Service
Machine learning consulting and development services from certified ML experts with a proven track record of delivering scalable ML-powered solutions.

Case study
Find out how Itransition’s dedicated team helped AiBUY release their innovative machine learning-driven shoppable video platform.

Service
Itransition offers ecommerce consulting services to help online businesses provide engaging digital commerce experiences and streamline day-to-day operations.

Service
Discover what opportunities ecommerce SaaS solutions open for online retailers and what limitations they should keep in mind before selecting a SaaS provider.
Services
Industries